
Author: Reilly Fastring
Artificial intelligence (AI) is now embedded in nearly every aspect of drone operations, from perception to navigation to higher-level reasoning. Yet as autonomous and semi-autonomous systems integrate into critical infrastructure, it also opens new attack surfaces. Data Poisoning, Adversarial Examples, and Sensor Manipulation can degrade or disable AI functions that drones rely on for safe and secure operation. What these threats share is that none of them show up in a conventional security assessment: they don’t trigger CVE scanners, they don’t fail hardware penetration tests, and they don’t get caught in supply chain reviews.
As reliance on these systems deepens, validating that the perception models that enables autonomous systems to perceive, navigate, and act are robust against adversarial conditions becomes a question of operational resilience rather than academic interest.

The Gap in the Stack
The security certifications currently available for uncrewed systems (UxS) validate that the platform is built securely, using trusted components, and following best practices for cybersecurity. These certifications are doing exactly what they were designed to do: validate the platform’s conventional cybersecurity posture and supply chain integrity. That’s not nothing — it’s a rigorous bar, and having such a certification is meaningful. The gap lies in what they weren’t designed to do.
A platform can pass every hardware and software security check, land on the cleared list, and still rely on a perception model that can be fooled by a printed piece of paper. The increasing adoption of perception-based autonomy has opened a new gap in the autonomy stack, one that adversaries have already begun to leverage.
Adversarial Threats
There are many ways to attack a perception model, but we are going to cover three adversarial threats on three different layers that are likely to affect perception models in the real world: Data Poisoning the Data Layer, Adversarial Examples the Model Layer, and Sensor Manipulation on the Sensor Layer.
Data Poisoning
Poisoned training data is arguably the most patient attack in the threat model. It requires neither physical access to the platform nor reverse-engineering the model. Say an adversary introduces corrupted or mislabeled samples into your training pipeline, perhaps through a third-party dataset or a compromised annotation vendor. The model trains normally, passing every validation metric. It ships.
And somewhere in its learned behavior is a hidden pattern waiting for a specific trigger to activate. A backdoor into the model. The attacker’s goal is to embed behaviors that surface only with specific triggers—a visible patch, a blended pattern, or a semantic attribute—making the corruption nearly invisible during standard testing. Researchers have even leveraged generative AI models to automate trigger injection for backdoor attacks. That said, the threat actor here doesn’t need to be an expert; all they need is to be in the training data supply chain.

Adversarial Examples
Our last threat was invisible and patient. This one is different – it’s loud and in your face.
Let’s say a perception model is tasked with identifying an object in a search area. An adversary on the ground places a printed pattern in the vicinity. It looks like abstract art. It’s obvious, but not obviously adversarial. But all of the sudden, the model cannot identify the object. Not because the camera is blocked. Not because the image is blurry. Because the nature of machine vision has been optimized to ignore it.
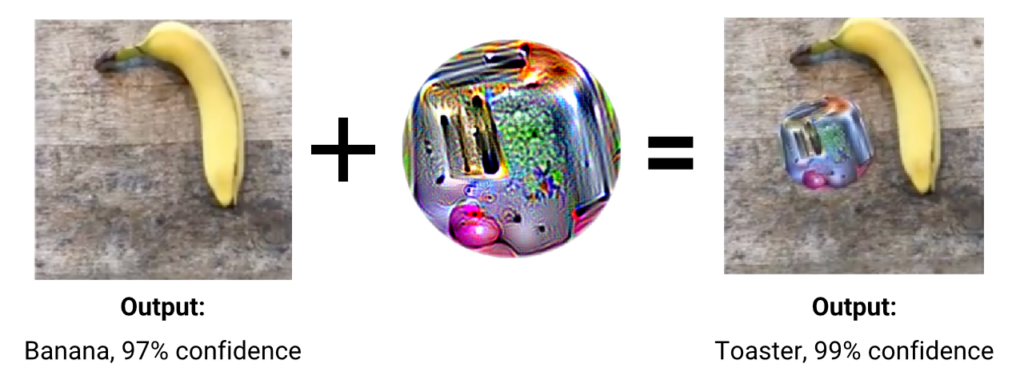
Attackers can place such adversarial patches above or close to a target, preventing the model from making stable and accurate identifications. And because the patch is printable and distributable, once again a threat actor doesn’t need to be a machine learning researcher to deploy one — all they need is a printer.
Researchers have even designed seemingly benign three-dimensional objects that can trick models into making wildly and dangerously incorrect classifications, such as this statue of a turtle:

Sensor Manipulation
Sensor manipulation doesn’t fool the model directly, instead corrupting the raw data before the model ever sees it. For example, an adversary can conduct spoofing attacks against LiDAR with a single laser, without directly tampering with the platform or altering packets in the network.

While these kinds of attacks predate modern autonomous systems, autonomy adds a new dimension to the threat. A human operator would eventually notice that something is wrong; a perception model simply interprets its surroundings incorrectly. What sets this threat apart from the others is the layer it operates on: you can’t harden a model against field data that was never real to begin with. The vulnerability isn’t the model — it’s in the architecture around it.
Tools and Mitigations
The question isn’t whether these threats are real or practical — the research is unambiguous in that regard. Rather, the question is whether you have the tools to mitigate them. The good news is that you don’t need to build those from scratch; the tools already exist, and many can be plugged into the autonomy stacks, development cycles, and models you’re already running.
Data Layer: Decontaminate & Mitigate
On the Data Layer, the goal is to decontaminate the training data and mitigate against any poisoning that may have slipped through.
SPECTRE detects and removes poisoned training samples before they can plant a hidden backdoor in your model, giving you a clean model without needing trusted validation data. It works by using robust covariance estimation to amplify the faint spectral signature that poisoned data leaves in a model’s internal representations, separating malicious examples from clean ones even when that signature is buried in low-variance directions.
TrojanZoo is an open-source benchmarking platform that enables systematic evaluation of backdoor attacks and defenses against your own models. It bundles together a library of representative attacks, state-of-the-art defenses, and standardized metrics. Instead of cherry-picking one defense and hoping it works, you can stress-test your model against many threats and see how each defense actually holds up.
STRIP flags trojaned inputs at runtime the moment they hit a deployed model, before the backdoor can fire. It works by superimposing each frame with random clean images and measuring how much the model’s predictions vary; clean inputs produce wildly different predictions, but trojaned inputs stubbornly classify to the same target class because the trigger dominates everything else. STRIP is a black-box add-on to any deployed model and catches triggers regardless of size or shape.
Model Layer: Benchmark & Harden
On the Model Layer, the goal is the benchmark the model’s performance against adversarial threats and harden it.
TokenFool is an Open-Source framework developed by TrustThink for running adversarial attacks specifically against transformer-based vision models. The existing frameworks were built around convolutional neural networks and pixel-level perturbations, but transformers have a fundamentally different structure that creates attack surfaces those older tools don’t cover. TokenFool fills that gap with transformer-specific attacks and allows users to support their own models through custom adapters without changing attack logic.
PatchCleanser neutralizes adversarial patch attacks — like the toaster example we saw — by masking out suspicious regions of the image. It works by sliding a set of masks across the input image and comparing model output; if the masks ever land on the patch, the model recovers the correct classification. PatchCleanser works with any state-of-the-art classifier and provides certified robustness.
PatchBlock detects and neutralizes adversarial patches before they reach your model, designed specifically for resource-constrained edge devices like drones. It works by chunking the image into small windows, using statistical outlier detection to flag regions that look suspiciously dissimilar from the rest of the image, then scrubs the adversarial signal out of those regions. PatchBlock runs on CPU in parallel with GPU inference, so it adds robustness without slowing the system down. It works with any model, any patch type, recovering up to 77% of accuracy under strong patch attacks.
Sensor Manipulation – Detect & Mitigate
On the Sensor Layer, the goal is to detect tampering and mitigate its impact.
Multi-modal consistency checks cross-validate the perception system’s reading against multiple independent sensors—typically camera and LiDAR—and flag the moments when those modalities disagree. The logic is that an attacker can usually only manipulate one sensor channel at a time: a LiDAR spoof won’t show up in the camera feed, and an adversarial patch won’t show up in the LiDAR point cloud. The trade-off is added cost and system complexity, but it gives you a defense that doesn’t depend on the model itself being robust.
A model-based plausibility check compares sensor input against what a mathematical model of the platform’s dynamics says the reading should or could be at that moment. The key distinction from a multi-modal consistency check is that you’re not asking whether two sensors agree with each other: rather, you’re asking whether a single reading agrees with the laws of physics governing the platform. A knowledge-based variant works similarly but cross-references the reading against an independent sensor measuring the same value, similar to multi-modal consistency checks.
ADoPT detects LiDAR spoofing attacks by tracking whether the points in each new frame line up with where the previous frames suggest they should be. Genuine objects have a continuous history across frames, but injected fake points appear out of nowhere, with no trajectory leading up to them, and that’s what ADoPT flags. The key advantage is that it works on the raw point cloud rather than on bounding boxes, so it catches small spoofed objects like pedestrians and cyclists that bounding-box-based methods tend to miss.
Need Help?
Frameworks and tools are only effective if teams understand how to apply them.
TrustThink provides consulting and testing/evaluation services for UxS developers supporting government, defense, and critical infrastructure customers. Our work helps manufacturers demonstrate compliance, reduce program risk, and prepare systems for operational deployment. Additionally, we provide a full suite of services—including domain-specific testing scenarios—to address evolving AI security requirements, with expertise across a wide range of models and data sets. We conduct comprehensive robustness testing to determine whether systems are hardened and resilient against potential threats.
Get in contact with our team to get started!
Sources
arXiv:1707.07397 [cs.CV]
arXiv:1712.09665 [cs.CV]
arXiv:2210.09482 [cs.CR]
arXiv:2306.00816 [cs.CV]
arXiv:2509.07504 [cs.CR]